Dependencies overview
By default, WhatsUp Gold polls all of the devices and active monitors on your Device List, often creating unnecessary overhead by polling devices whose state could be assumed based on the status of other devices. The dependency feature reduces polling overhead in these cases by allowing you to create conditions under which a device will not be polled. These conditions determine if a dependent device is to be polled based on the state of another device which is the target of the dependency. The state of the target device is determined by the state of one or more of its active monitors. You can establish dependencies on either the up or down states of these active monitors, resulting in Up dependencies or Down dependencies.
Up Dependencies
An up dependency establishes a condition so that a device is polled only if the selected active monitors on a second device are in the up state. The device can be thought of as being “behind” the device to which it has a dependency, so that it will only be polled if the device "in front" of it is up.
Example
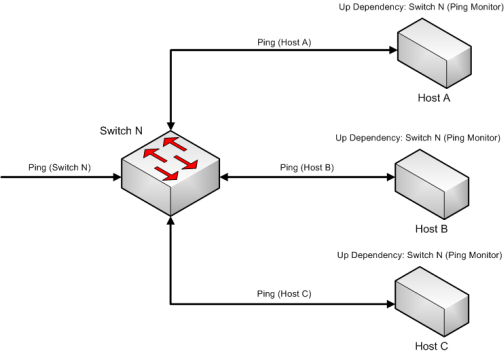
In this example, an active monitor has been configured for each of the devices, and is denoted using Ping (device_name). Without dependencies, WhatsUp Gold attempts to poll the Ping monitors on the hosts even if the switch has been powered down, or is otherwise unreachable. This situation results in network and system overhead that could be avoided by creating up dependencies on the hosts.
By adding an up dependency on each host so that the polling of the hosts is dependent on the Ping monitor on Switch N being up, denoted Up Dependency: Switch N (Ping Monitor), you create the condition where WhatsUp Gold discontinues polling the hosts when Switch N is powered down or otherwise unavailable to the Ping(Switch N) monitor. This reduces the overhead required to monitor the dependent host devices, while providing information about their accessibility based on the accessibility of Switch N.
Down Dependencies
Important: If you use the APM plug-in and have APM components that include WhatsUp Gold devices with dependencies, be aware that APM components honor both WhatsUp Gold Unknown and Maintenance device states as Unknown states. Therefore, if a WhatsUp Gold device goes into an Unknown or Maintenance state, the APM component will change to an Unknown state. For more information about how device states roll up from individual APM component status to the overall APM instance state, see Learning about APM component's instance state precendence.
A down dependency establishes a rule so that a device is polled only if the selected active monitors on a second device are in the down state. The device can be thought of as something is “in front of” the device to which it has a dependency. The dependant devices in front will not be polled unless the device further down the line is down.
Example
In this example, a network segment has a group of devices, each with a dependency on another for its connectivity. Each of these devices has a Ping monitor used to determine the state of the device, denoted Ping (device). If Host A can be pinged from another network segment, then it can be assumed that Router R, and Switch N are up and available, so to operate separate ping monitors on these devices creates unneeded overhead as long as Host A is up. However if Host A is powered down, or otherwise unreachable by the Ping monitor, we must rely on the Ping (Switch N) and Ping (Router R) monitors to ensure that these devices are up and accessible.
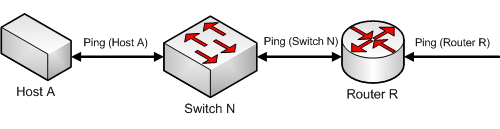
Adding a down dependency on Switch N to the Ping monitor on Host A, Down Dependency: Host A (Ping Monitor), and a down dependency on Router R to the Ping monitor on Switch N, Down Dependency: Switch N (Ping Monitor), creates a chain of dependencies that will monitor the network segment and reduce the active monitors that must operate on the segment when it is fully operational.
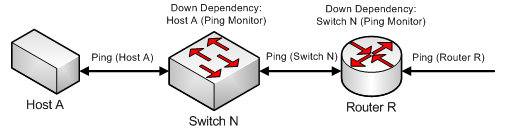
With these dependencies added, if Ping (Host A) should go into a down state, the down dependency on Switch N will cause WhatsUp Gold to begin polling Switch N. If the polling of Switch N is successful, it will continue to be polled until Host A is recovered. However, if Switch N is also unreachable and Ping (Switch N) goes into a down state, the down dependency on Router R will cause WhatsUp Gold to begin polling Router R. When Ping (Switch N) returns to an up state, Router R will no longer be polled. Likewise when Ping (Host A) returns to an up state, Switch N will no longer be polled.
Down dependencies and the "assumed up" state
A down dependency on a device can lead to an "assumed up" state, where a monitor on the dependent device indicates that it is up, regardless of its actual state.
This condition occurs when the dependent device is in an inactive state, and is able to respond to an echo request from a ping of the device. Because of the down dependency, the dependent device is not being polled and is "assumed up", yet the actual state of the monitored service or process is unknown, and may have even failed.
An example of the dependent system would be a passive, or standby server, in support of a high-availability (HA) database cluster that has a down dependency on the active server. If the database management system (DBMS) on the standby server fails to start on a reboot, WhatsUp Gold will not show this failure until the active server fails and the standby server is polled.
Reading dependencies
There are several ways to "read" dependencies to ensure they are applied as you want them.
- Review the description of the dependency in the Device Properties dialog.
- Read the dependency arrows in the Map View.
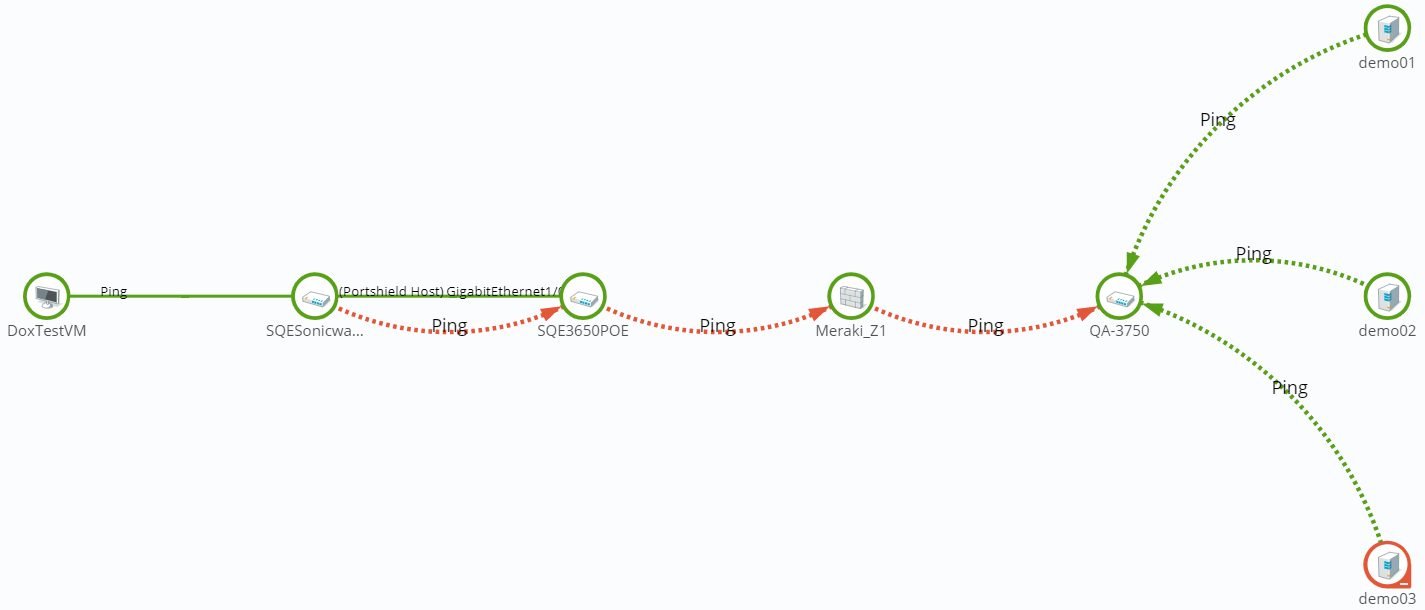
The map above displays several Up and Down dependencies. The green arrows indicate an Up dependency, and the red arrows indicate a Down dependency.
Using the "behind" and "in front" terminology you can follow the graphical arrow in the map above to read a dependency. For example, the server dependencies are read as, "only poll the servers if the switch is up." The servers are behind the switch, and will only be polled if the switch is also responding to polls. If the switch goes down, the server is assumed unavailable and is no longer be polled. Since the server is unavailable, the server's state then changes to Unknown.
For another example, the router dependency on the firewall is read as, "only poll the firewall if the switch is down." If a break in communication takes place between the router and the firewall, the switch changes to the Down state because it is Down dependent on the firewall. If the switch goes down, the state of the servers changes to Unknown, because they are Up dependent on the switch. Then, since the switch is down, the firewall is polled and changes to the Down state. After the firewall is considered down, the router is polled.
Down dependencies are useful in showing the break position in a chain of machines. If the chain is not broken at any point, the machines in the chain are not polled and are assumed up.